
Recently I have published my Trainmonitor app, that is using a backend server to get the train data and do the notifications. To communicate with the server I have an HTTP API, some people might call it a RESTful API, but we will see later that this is not the case. There are several issues with the API, part of the done intentionally done wrong and others not. So why would I do stuff wrong if I knew it was wrong? Do demonstrate what’s wrong and to show what the benefit is when you do a real RESTful HTTP API with hypermedia. The idea about this came to me when I ret this blog post about HTTP APIs at XING. What the API currently is, is some kind of remote method invocation over HTTP.
So what’s wrong with the API?
Let’s have a look at some URIs:
http://trainmonitor.logv.ws/api/v1/germany/stations
http://trainmonitor.logv.ws/api/v1/germany/trains
At first you can see there is some kind of version in the URI. In a RESTful world this should not be needed. The data the API responses should guide the client through the resources. There should just be a single URI you need to know to discover the hole API. We will talk about this later, so lets have a look at a typical request - response: For testing purpose I am issuing a request from Chrome to _http://trainmonitor.logv.ws/api/v1/germany/trains_:
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Charset:ISO-8859-1,utf-8;q=0.7,*;q=0.3
Accept-Encoding:gzip,deflate,sdch
Accept-Language:de-DE,de;q=0.8,en-US;q=0.6,en;q=0.4
Cache-Control:max-age=0
Connection:keep-alive
User-Agent:Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.97 Safari/537.11
The server response headers looks like this:
Cache-Control:public, max-age=105
Content-Encoding:gzip
Content-Length:28515
Content-Type:application/json
Date:Tue, 08 Jan 2013 20:41:44 GMT
Keep-Alive:timeout=15,max=100
Server:Mono-HTTPAPI/1.0
[{
"train_nr": "ICE 576",
"status": 4,
"stations": null,
"started": null,
"nextrun": "2013-01-10T12:21:00Z",
"finished": null
}, {
"train_nr": "ICE 37",
"status": 4,
"stations": null,
"started": null,
"nextrun": "2013-01-10T14:23:00Z",
"finished": null
}, {
"train_nr": "ICE 909",
"status": 1,
"stations": null,
"started": "2012-12-08T09:30:01.742Z",
"nextrun": "2012-12-08T15:49:00Z",
"finished": "2012-12-08T15:56:52.916Z"
}]
According to the header we got some gzip compressed JSON that can be cached for the next 105 seconds. But we don’t really know what the response contains, except it is some kind of JSON. This means the consumer needs more out of band knowledge to be aware how to process the data. When we look at the payload, the JSON, we see there are no links, but some IDs. If the client now wants to access other resources that have a relationshilt to this one the client needs to know where to find this resource. Once again out of band knowledge is needed.
How to fix the mess?
Lets start with the problem that the client needs to know the complete URI layout of the server. Wouldn’t it be nice if the client only needs to know a single URI?. This URI might be _http://trainmonitor.logv.ws/api/_ and the server responds with something like this:
Cache-Control:public, max-age=86400
Content-Encoding:gzip
Content-Length:28515
Content-Type:application/vnd.logv.trainmonitor-discovery+json
{"links":[{"rel":"germany","href":"http://trainmonitor.logv.ws/api/germany"}]}
As you can see the Content-Type is now application/vnd.logv.trainmonitor-discovery+json and you might notice that I am using the non standard +json suffix. This is currently in draft status to update the +xml RFC. My mediatype vnd.logv.trainmonitor-discovery is a ripoff of the html link element, extended with some more semantic for the rel element. The client now knows that the data is formatted as JSON and what this JSON means. If the client wants to get more information about germany it knows that it should issue a GET request to _http://trainmonitor.logv.ws/api/germany_. And the server should answer with:
Cache-Control:public, max-age=86400
Content-Encoding:gzip
Content-Length:28515
Content-Type:application/vnd.logv.trainmonitor-discovery+json
{
"links": [{
"href": "http://trainmonitor.logv.ws/api/germany/staions",
"rel": "stations"
}, {
"href": "http://trainmonitor.logv.ws/api/germany/trains",
"rel": "trains"
}]
}
As before the Content-Type is application/vnd.logv.trainmonitor-discovery+json, but we see some new rel data. When the client parses the response data it finds the information where to find the stations and trains for germany. All responses contain a Cache-Control header with a value of 864000 seconds, this allows the client or any other cache on the way from the origin server to the client to cache this resource for a day. This way the origin server is not hammered with requests for discovering the resource layout and the clients can reuse a fresh resource without contacting the origin server, but after at least 24 h they will ask you again. Why is this good instead of hardcoding the URIs? Once your services grows you might experience more load on the server and single server might not be able to answer all the requests in reasonable time. So you need to scale horizontally. To do this you can reroute all the request for a single country to another server. Or you can have single server for stations and one for trains or mixing it all together. E.g. having a single server for the stations of all countries but one server for each countries trains, because this data changes much more often and is more interesting to the clients. To do so no change on the clients is required, all of them will use the new infrastructure without touching them.
What about Links?
After that we have talked about the URIs and how the client gets to know them, lets have a look at the resources and its representation. We start with the stations from _http://trainmonitor.logv.ws/api/v1/germany/stations_. A typical response looks like this:
Cache-Control:public, max-age=86400
Content-Encoding:gzip
Content-Length:28515
Content-Type:application/json
[{
"lat": 47.5500209,
"lon": 14.3122344,
"name": "Selzthal",
"id": 380
}, {
"lat": 52.5104217,
"lon": 13.4969506,
"name": "Berlin-Lichtenberg",
"id": 394
}]
What’s wrong here? The Content-Type! From the header the client just knows that it is some kind of JSON, but has no clue whats the containing JSON means. The client would need to know that this particular URI returns a list station objects. To fix this, the Content-Type might look like this application/vnd.logv.trainmonitor-stations+json. And what about the Cache-Control? 24 hours freshness??? Yes, this is valid, because of the fact that the backend server only refreshes the station list, from its data source, once a day this resource can be cashed a full day.
Now lets move on to the more interesting trains. A response from _http://trainmonitor.logv.ws/api/v1/germany/trains_ looks like this:
Cache-Control:public, max-age=105
Content-Encoding:gzip
Content-Length:28515
Content-Type:application/json
[{
"train_nr": "ICE 576",
"status": 4,
"stations": null,
"started": null,
"nextrun": "2013-01-10T12:21:00Z",
"finished": null
}, {
"train_nr": "ICE 37",
"status": 4,
"stations": null,
"started": null,
"nextrun": "2013-01-10T14:23:00Z",
"finished": null
}, {
"train_nr": "ICE 909",
"status": 1,
"stations": null,
"started": "2012-12-08T09:30:01.742Z",
"nextrun": "2012-12-08T15:49:00Z",
"finished": "2012-12-08T15:56:52.916Z"
}]
Once again the Content-Type is too general and should be more precise like application/vnd.logv.trainmonitor-trains+json. The Cache-Control is now much shorter, why? The server refreshes trains on schedule and calculates the time to the next refresh when a client issues a GET request. Then it sets the Cache-Control header according to this value. Now a closer look at the JSON content and why this is clearly not a hypermedia type. Why is the stations property always null? This requires some explanation … In the domain data model the stations property is a list off all stations of each train with arrival, departure and delay times. A complete list of all trains contains about 1300 trains. Also the client is not interested in all the trains and its delays. That is why I decided to omit this value in the train list and only include it when a single train is requested. But how do we get this data? Good question, once again the client need out of band information that is not part of the conversation with the server. The URI template for a train looks like this _http://trainmonitor.logv.ws/api/v1/germany/trains/{train_nr}_. For the ICE 909 this would be _http://trainmonitor.logv.ws/api/v1/germany/trains/ICE%20909_. In order to solve this issue we need to include this information in the reposen. A response might look like this:
{
"train_nr": "ICE 909",
"link": {
"href": "http://trainmonitor.logv.ws/api/v1/germany/trains/ICE%20909",
"rel": "train"
}
"status": 1,
"stations": null,
"started": "2012-12-08T09:30:01.742Z",
"nextrun": "2012-12-08T15:49:00Z",
"finished": "2012-12-08T15:56:52.916Z"
}
Simply by addeing a link attribute the client knows where to find the resource. But still the stations attribute is null, so lets fix that in a similar way:
{
"train_nr": "ICE 909",
"link": {
"href": "http://trainmonitor.logv.ws/api/v1/germany/trains/ICE%20909",
"rel": "train"
}
"status": 1,
"stations": {
"href": "http://trainmonitor.logv.ws/api/v1/germany/trains/ICE%20909/stations",
"rel": "stationdetails"
}
"started": "2012-12-08T09:30:01.742Z",
"nextrun": "2012-12-08T15:49:00Z",
"finished": "2012-12-08T15:56:52.916Z"
}
Just like before a link element lets client know where to find it. The other resources contain similar fails, so I will not discuss them here, it would get boring for you to read the same over and over again.
Why should I use hypermedia?
This is easy! Because you gain a lot of flexibility and get a loosely coupled system. But is it worth to do so? Isn’t the client getting much more complex?
I will compare which information the client need before and after using hypermedia.
Before
- data type for trains
- data type for stations
- data type for stationdetails
- URI template for trains
- URI template for stations
- URI template for a single train
- URI template for stations of a train
- connection between each URI (template) and its datatype
To visualize this I drew a little diagram with the direct relations between the resources.
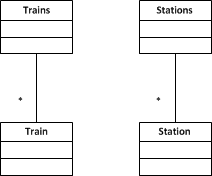
After
- data type for trains
- data type for stations
- data type for stationdetails
- data type for discovery
- a single URI
And that is how the diagram now looks:
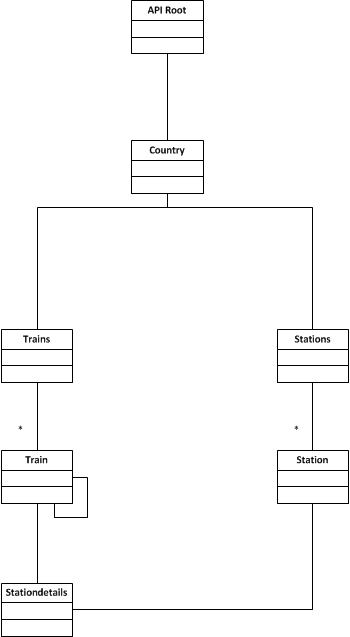
As you can see all the resources now have explicit connections, instead of beeing just two independant islands, that were connected with out of band knowledg.
Some people might argue that implementing a client that can follow links and parse a slightly more complex data type requires more work to. That might be true! But is it really that much more work to do? Using a URI from an resources attribute or formatting a attribute of a resource into a template is not that much different!
But you must put more work into the design of your resources and decouple them from their representation. The task is not: how do publish my domain model as JSON or XML It is: how should the resources for my domain model look like and how is their relationship to each other. After you have an abstract model of your resources you can think of how to represent them. Depending on your needs you might have a single data type for your whole domain. Which is often the case when you use XML, because XML offers more semantics than, e.g. JSON. But you can either find ways to do so in JSON. On the other hand you can use a data type for each kind of resource.
OK, but where is the API?
While I was writing this post I decided not to publish a API documentation, right now! As you can see there are several issues with it. I wrote this post to show other people in which traps I have gone and how fix / avoid them. I will redesign the API in the next weeks and reimplemt the client side completly. After that I will publish a complete API documentation and open the API for everyone. In the meantime you can have a look at the trainmonitor android app which just got open sourced!