
Context Boundaries in Language Engineering Projects
Created Jan 8, 2021 - Last updated: Jan 8, 2021
How to scale your language engineering project beyond a single team without causing a communication and dependency hell.
A question commonly asked in the context of language engineering projects that create a Domain Specific Language (DSL) is: how to scale and structure teams? In this blog post I’m going to show patterns for distributing ownership of parts of the project, which ones to avoid and which work best. Clearly defined contexts and ownership of them is crucial for teams to collaborate and a key concept in Domain Driven Design (DDD): the bounded context. We are going to look at a typical language engineering project and identify potential bounded contexts.
While DDD skills and methodology are widespread in software engineering, language engineering is a niche community. Connecting these two communities can be challenging because terms might have different meanings in the two communities. For instance the term language has a very distinctive meaning in the context of Domain Driven Design and a somewhat different one in the context of language engineering. To avoid potential confusion this post will explain specific terms explicitly to avoid confusion.
Context Mapping is common technique used in Domain Driven Design to illustrate the different Bounded Contexts, their owning teams and dependencies to other parts of the system. A context map also includes the type of pattern that describes the kind dependency between two contexts. In this post we will not look at these pattern in greater detail but focus on identifying context boundaries and their implications.
As an example for this post I will use a medium sized Domain Specific Language project which is representative majority of DSL projects. Medium sized means that it is a project scoped to one department of an organization which potentially affects more than one team but isn’t trying to introduce DSLs strategically through large parts of the organization. To keep the scope under control we will look at the project in isolation and intentionally exclude its external dependencies like the language workbench or a “base language” used to implement the domain specific language. The fictional project takes place in the domain of social benefits and develops a DSL that used to describe all aspects required calculate the benefits a person is able to receive and generate a Java program that is then used in desktop application as a calculation core.
Potential Contexts
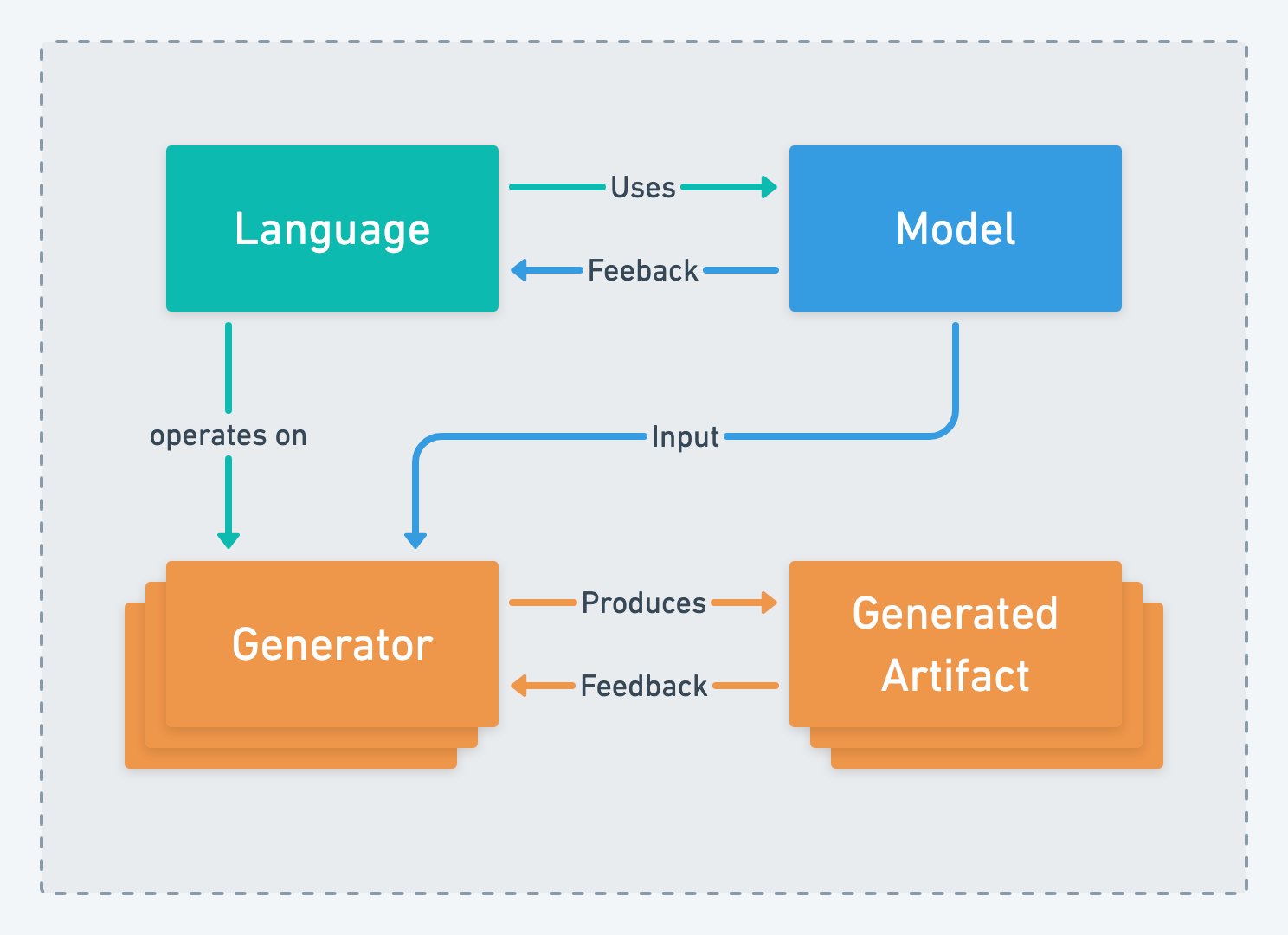
Before we can look at the what the implications of dividing contexts in particular way we need to identify where context boundaries can be placed. There are typically four candidates for separate bounded contexts in a DSL project: Language, Model, Generator and Generate Artifact.
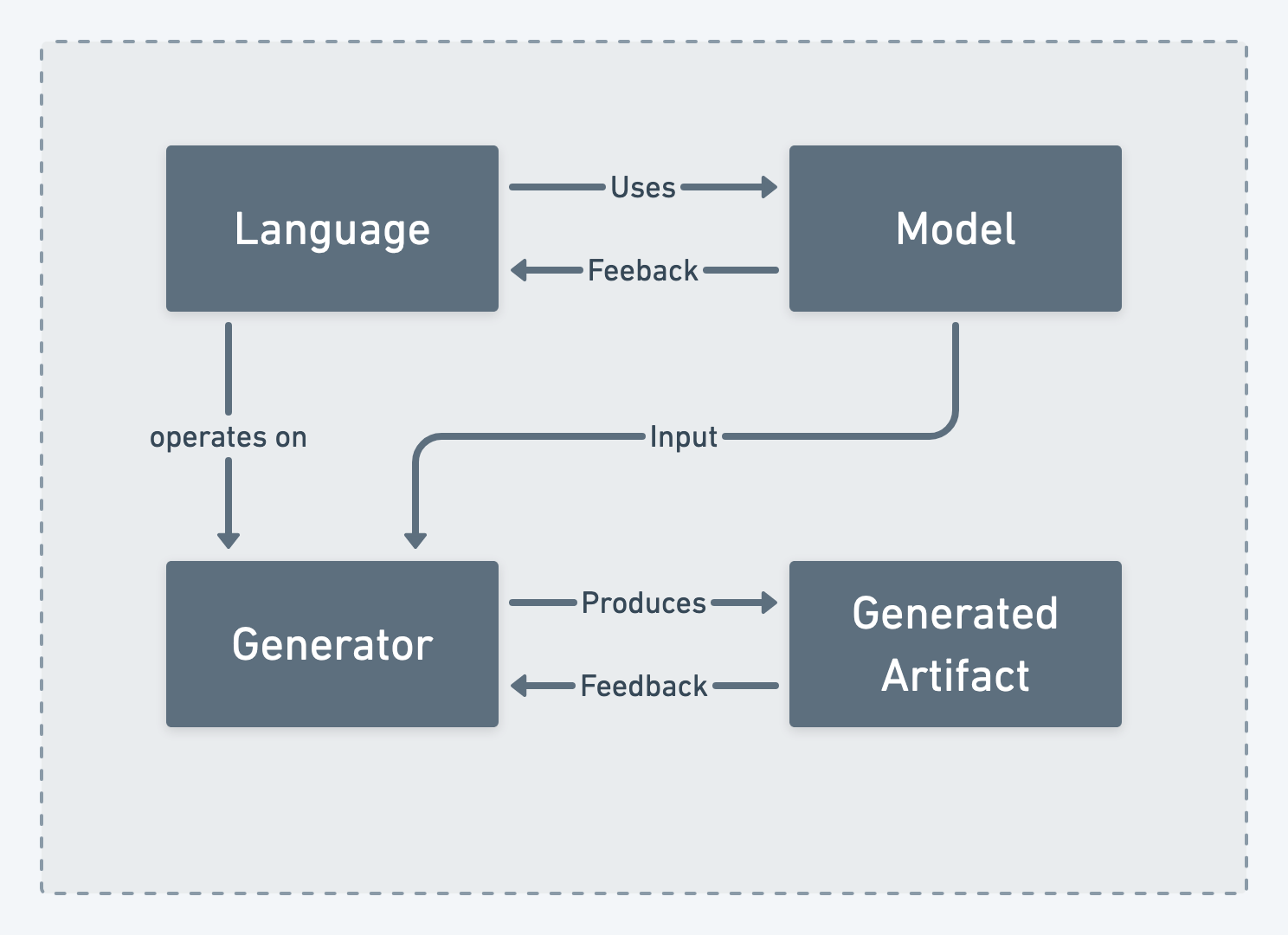
Language
Language in language engineering is not be confused with the term ubiquitous language which is used in domain driven design. Language in language engineering is not only the meta mode that is used to construct a model but includes everything to make the meta model usable by the user. The language includes the tools build to allows user to interact with the model, this includes things like syntax highlighting, auto completion, consistency checking and other means to support the user. In a general purpose programming language you would call this an IDE.
A language has a concrete syntax that the user interacts with and an abstract syntax which you can think of as the internal data structures of the language.
The development the language is done by language engineers in close cooperation with the domain experts. The language is then used by the domain experts to construct the model.
Owning the language means being responsible for everything used to create and interact with models created from that language as well as maintaining the internal data structures (meta model) used to represent the domain.
Model
The model is constructed of instances of the meta model of the language. A model is created by domain experts that know the details of the domain and encode them using the language. Domain experts are usually not programmers. In a “classical” software engineering project domain experts would be writing requirements for features of the system which are then implemented by software engineers.
The domain experts work in close relationship with the language engineers to ensure the language allows them express the concerns of the domain as desired. The feedback and input of the domain experts is essential for the language engineers to define the semantics of the language.
Owning the model means being responsible for creating a complete and correct representation of the domain using the tools provided by the language.
Generator
A generator is piece of software that takes one or multiple models and transforms them into a generated artifact. The models are fed into the generator as an abstract syntax tree (AST) and then transformed into the desired output via templates. In order to understand the AST the generator needs to know the meta model behind the language.
In our example project the generator will take calculation rules, parameter data, etc and convert them into a Java program executing the calculations and interacting with surrounding infrastructure e.g. data store and user interface.
Owning the generator means being responsible for maintaining the templates and rules that transform a model into the generated artifact and reacting to changes in the language to ensure the transformation happens correctly.
Generated Artifact
A generated artifact is an artifact created by the generator. These artifacts could be programs or representations of (parts of) the model in a data exchange format.
Why is it important to list this separately when it’s the result of the generator execution? Responsibility for running the artifact is easily overlooked and can cause a responsibility vacuum between teams if not clearly defined. The artifact might pass all automated tests and conforms to the specification but cause problems when deployed into the system. This problem is often seen with none functional requirements on the artifact.
In our example this could be that the resulting Java program compiles correctly, passes all the test cases and is successfully deployed into production but doesn’t meet its performance goals or consumes to many resources.
Owning the generated artifact means being responsible for the correctness of the artifact (e.g. by applying automated tests and validation), its deployment and running the artifact within the system.
Patterns for Context Boundaries
Lake
A Single Team
The simplest and most obvious organization of the four potential contexts is putting the responsibility for all four into a singe team:
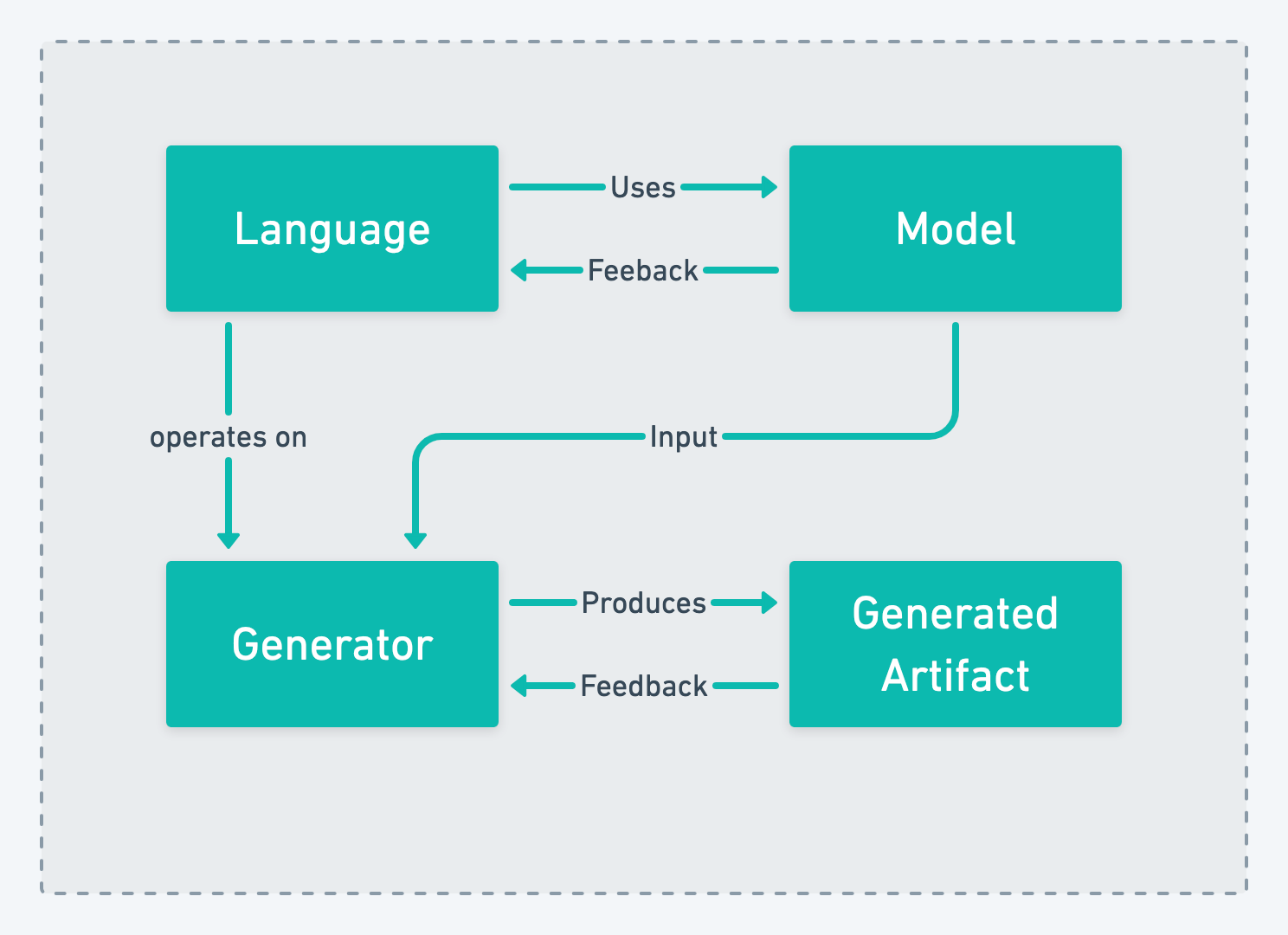
This organizational pattern keeps all communication within the same team and avoids crossing a team boundary. It allows a close relationship between the domain experts and language engineers for the evolution of the language. Domain experts cam easily give feedback on new features integrated into the language while also maintaining the generator at the same time by the same team. Because the same team that is responsible for the evolution of the language owns the model changing the model along with the language is easy and breaking changes to language are often feasible.
The pros of this approach are control over every aspect of the project and the close relationship with the domain experts. The downsides are potentially huge scope, that becomes unmanageable over time, and wide required expertise in the team that ranges from domain expert and language engineers to experts on the generated artifacts.
This pattern is typically how projects start because the allow a very close collaboration between the domain experts and the language engineers but is eventually outgrown when then amount of users of the language increases and would grow the team beyond a manageable size.
The name originates from the fact that everything is contained in a single team and has a clear “coastline” surrounding it.
Floating Iceberg
Domain Experts and Language Engineers
Eventually a project will outgrow the “Lake” approach which might happen because of team size or to separate the language development concerns from the domain experts. The goal of the Floating Iceberg is to allow both parts (model and language) to evolve in close relationship but organizational independence. The obvious way to achieve this is by creating a separate team of domain experts which is responsible for modeling the domain:
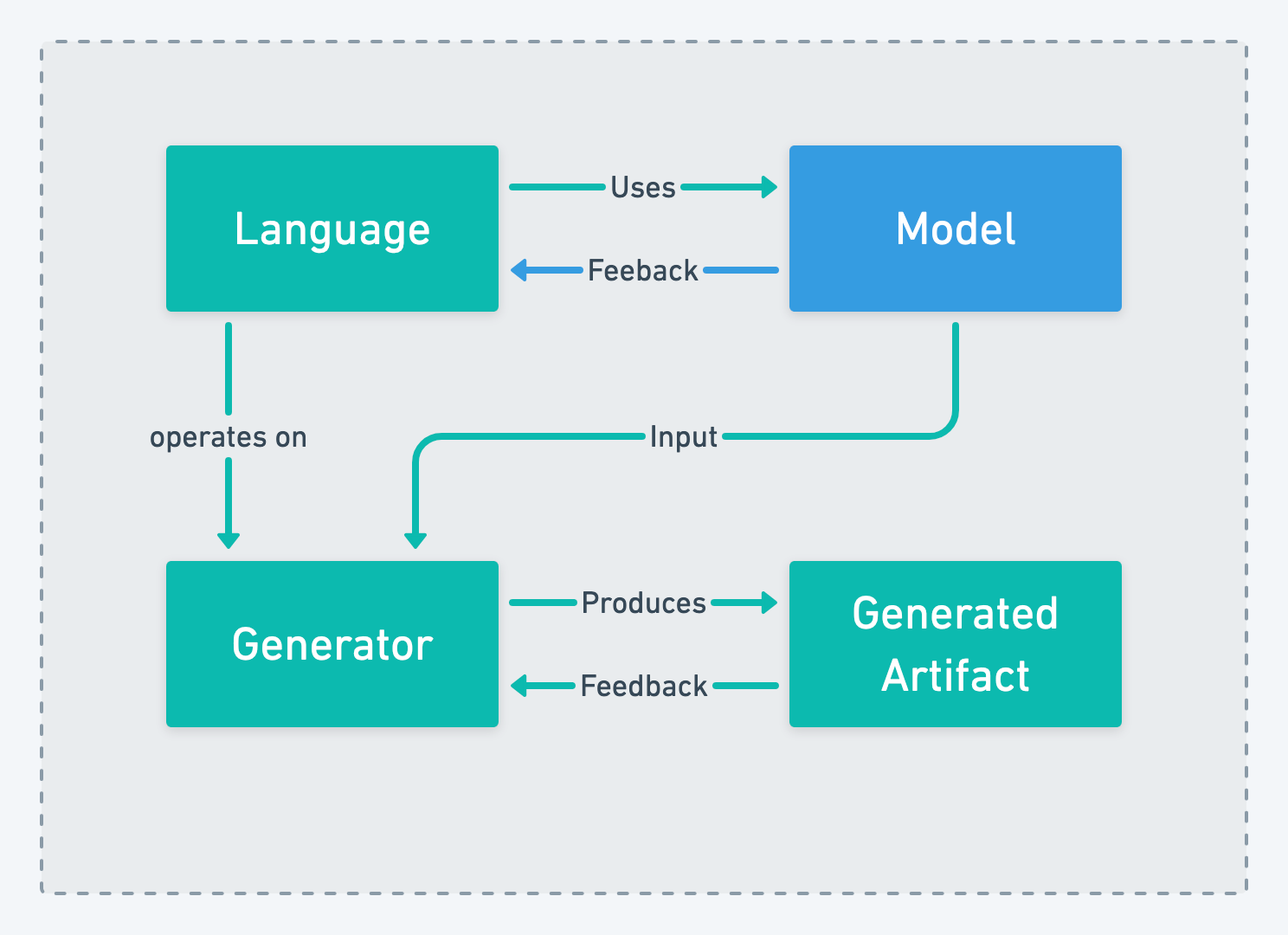
Separating the two contexts gives both teams more autonomy about their inner workings. Both teams for instance are free to choose their own increments in which they deliver their work and govern the process how they get to their results. Domain experts often prefer process frameworks with less ceremony like Kanban, while language engineering teams, often deeply rooted in software engineering, will prefer to stick to something like scrum to organize their work. It is important to understand that deadlines for the domain experts might be imposed by the domain e.g. if the domain is closely related to taxation the deadline for a new set of calculation rules is imposed by the date when a new taxation law takes effect.
While this approach gives autonomy to both teams it also creates a strong dependency between them. The domain experts won’t be able to deliver their results if left unsupported by the language. On the other hand generating correct artifacts from a model might not be possible for language engineering team without a clear understanding of the semantics of the model created by the domain experts. This dependency requires both teams to work closely together. The language engineering team needs to be aware of deadlines affecting the domain experts to be able to prioritize their work, while the domain experts need to reserve enough time and communication bandwidth to shape features language to their needs.
The pros of this approach are independence between the two teams, which is often liberating for the domain experts, and the possible to scale the size of each team. The downside of this approach is the dependency between the two teams. New requirements or feedback to the language need to cross a team boundary which is of course more “expensive” than keeping it in the same team. In order to meet deadlines the domain experts depend on the language engineering team to deliver required features to the language in time. But this dependency is not a oneway dependency on the language engineering team, because language engineering team owns the generated artifact and therefor the “implementation to of the domain in code”, it is dependent on the domain experts to model the domain in time to generate code from the model. While on first glance this looks like an undesired state it acts as an incentive for the language engineering team to provide a high quality language in time.
The name originates from the fact that some aspects of language is made public, the tip of the iceberg, while the majority of details is hidden below the language engineering teams surface.
Desert of Dependencies
Programming Domain Expert fighting Language Engineers
A pattern that comes up surprisingly often in organization that look for a team structure when apply language engineering is: creating a team that entirely focuses of the language engineering aspect and another team is responsible for modeling the domain with the language and owning the generated artifact:
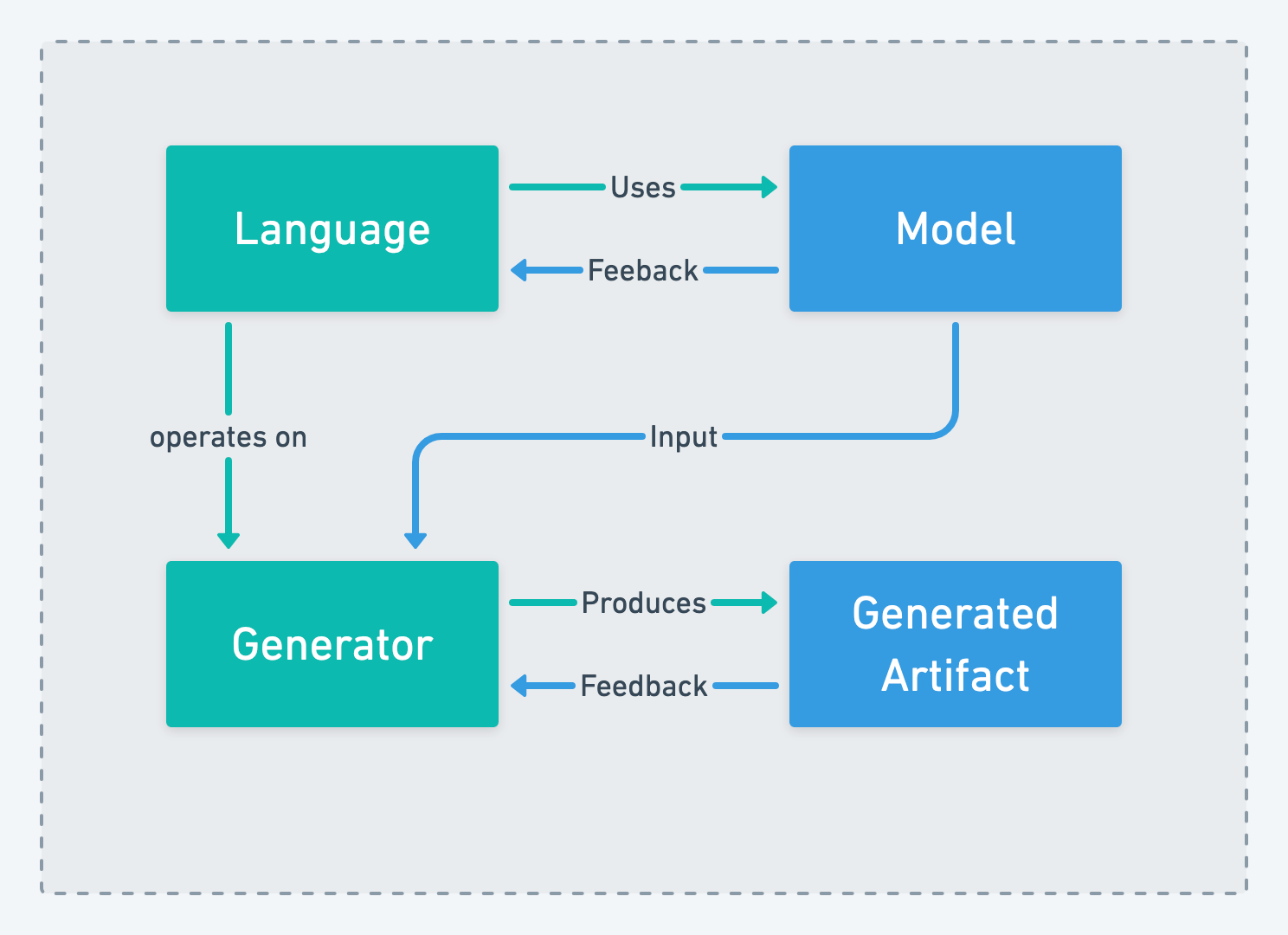
The two most encountered reasons for considering this pattern is trying to mitigate the two way dependency created by Floating Iceberg and that it is similar how the relationship with “normal” programming languages work.
Trying to capture the language engineering knowhow in a single team and allowing it to completely focus on it seems beneficial. The problem with this pattern is that the team responsible for the model and the generated artifact is entirely dependent on the language engineering team for delivering anything. While the dependency on the language is the same as in the “Floating Iceberg”-pattern this pattern adds the generated artifact to same communication channel. One side effect of this pattern is that the generator now becomes a public contract between the two teams. By the nature of how languages are developed the generator can lack behind the language implementation, especially for language features that are in an exploitative state the language engineering team often hesitates to implement the generator at the same time as the language is implemented. With iterative time boxed approaches like scrum the generator implementation can lack one or two iterations behind the language when using this pattern.
The perceived pros to this pattern do not really materialize when taking a closer look and are easily turned into cons, this makes this organizational structure an anti-pattern that you want to avoid at all cost.
The name originates from the fact that the team responsible for the model and generated artifact feels like being dried out by their huge dependency.
Steam Turbine
Generating Domain Experts and Language Engineers
When looking at the “Desert of Dependencies”-pattern one might think that drawing the context boundary a little different and separating the language from everything else including the generator into another team might overcome its limitations.
In practice, while not being as bad as the “Desert of Dependencies”, it still has a significant downside: the implementation details of the language (meta model) become a contract between the two teams. If possible you want to avoid this pattern for the increased dependency surface and the resulting communication efforts between the two teams.
Modeling at Scale
In many cases scaling to two teams is enough but if you need to scale beyond that you need to take a close look at the reasons for scaling in order to decide how to scale. If your reason for scaling is that you want to work with a larger group of domain experts on the models than feasible in a single team the natural way is to create multiple “model” teams that are working independent. In this case it’s often possible to maintain a single language engineering team that serves the domain expert teams, especially when the language is already mature and doesn’t undergo much exploitative development. You can think of this as the “Floating Iceberg”-patter with multiple model teams.
A different reason for scaling is that you have many different teams being interested in generated artifacts from the model(s). An example for this might be you have build your own systems engineering tooling which is then used by system engineers to model systems from your domain and you want to generate different artifices from these models e.g. AUTOSAR files, network hardware configuration files, C and Java code for the data used in the system or system start up configuration files. Now if you payed close attention to the patterns you are most likely tempted to go with “Floating Iceberg” with a large part of the team dedicated to the generator.
While going with that pattern seems to be beneficial as it contains the language engineering knowhow in a single team and avoids making the implementation detail of the language a contract between two teams it can easily overwhelm the language engineering team. In order to be able to fully own the generated artifacts the language engineering team needs to have experts for these formats and the use case on the team. The language engineering team in addition needs to ensure the artifacts conform to the contract associated with them and are delivered on time. This pattern easily shifts significant parts of your limited team size away from language engineering into the generated artifacts. It can in the long run limit the ability to evolve the language at a rate demanded by the domain experts and put the language engineering efforts as a whole in question because it makes language development look slow.
A better way of dealing with this situation is to place (some) generator aspects out of the language team and put it the ownership for these generators and the artifacts into the teams that request these artifacts:
Choosing this solution makes the implementation details (meta model) of the language a contract between teams and require some language engineering knowhow to be present in multiple teams. The facts that the meta model is now a contract between teams will pose some constrains on the language team to avoid regular breaking changes for the teams maintaining their generators. These additional constraints are easier to handle with documentation and communication between the teams than the risk of scope creep in the language team. Kick starting this pattern usually involves a period where the language team seeds their language engineering knowhow into other teams with trainings, coaching or even sending team members to other teams for a limited time.
In many cases the language team doesn’t hand of all generators to other teams and owns one or more “core” generators and artifacts. The ownership decision takes into account how many implementation and semantic details of the language the generator needs to know to produce the artifact. If the generators dependency on implementation details is large then it makes sense to keep ownership of that generator in the language team to maintain a working generator while the language evolves.
Conclusion
As you can see scaling a language engineering project is no different from scaling any other (software) projects beyond a single team. It is important to understand the context that a team owns, what dependencies it causes and what contracts are associated with these dependencies. Not only for an organization new to applying language engineering it can be a challenge to identify patterns for scaling beyond a single team. I hope this blog post helped to identify patterns and their implications. In a future blog post I will take a look at different types of dependencies between teams in the context of language engineering and classify them using domain driven design terminology.
If you liked the content consider subscribing to the email newsletter below which delivers all new post directly into your inbox. For feedback or discussions on the topic feel free to reach out to me on Twitter @dumdidum or via mail to kolja@hey.com.